
Indexdekking voor Google Search Console?
Het Indexdekking rapport van Google Search Console is bedoeld voor de status van de indexering van je website pagina’s.
{kind=link}
Statusrapport voor indexdekking
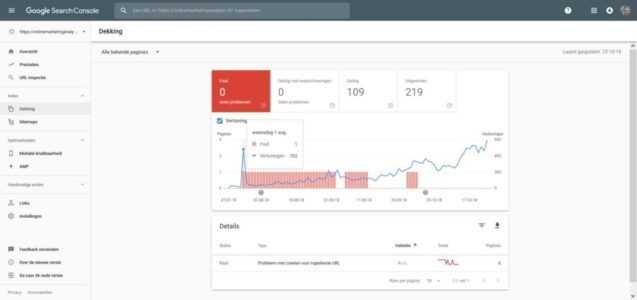
Met het rapport indexdekking kun je achterhalen welke pagina’s van je website zijn geïndexeerd en hoe je je pagina’s kun verbeteren die niet kunnen worden geïndexeerd. Iedere balk in het diagram vertegenwoordigt het totale aantal URL’s met een bepaalde status (geldig, fout enz.) zoals bekend is bij Google.
Waar je in dit rapport op moet letten
Normaal gesproken zie je het aantal geïndexeerde pagina’s toenemen naarmate je website groter wordt.
- Je ziet een piek in de indexeringsfouten: Mogelijk wordt dit veroorzaakt door een wijziging in je template waardoor een nieuwe fout wordt geïntroduceerd. Het kan ook zijn dat je een sitemap het verzonden die URL’s bevat die zijn geblokkeerd tegen crawlen (bijvoorbeeld door robots.txt, noindex of inlogvereisten).
- Als je een daling ziet in het totale aantal geïndexeerde pagina’s zonder overeenkomende fouten: Dit zou kunnen betekenen dat je de toegang tot je bestaande pagina’s blokkeert (door robots.txt, noindex of vereiste autorisatie). Mocht dit niet het probleem zijn, bekijk je de uitgesloten redenen, gesorteerd op het aantal betreffende pagina’s, om te achterhalen wat deze daling kan hebben veroorzaakt.
- Als je een groot aantal pagina’s hebt die niet zijn geïndexeerd: Ga alle uitgesloten URL’s na om na te gaan welke pagina’s wel ouden moeten worden geïndexeerd. Het zou kunnen zijn dat je heel veel van je pagina’s automatisch blokkeert of heb voorzien van een noindex-tags.
Hoe worden deze URL’s gevonden? Google ontdekt URL’s op vele manieren, meestal door links van gecrawlde pagina’s te volgen of via sitemaps. Soms zijn deze links verkeerd (en kunnen ze 404-fouten op je site veroorzaken).. Soms heeft deze pagina bestaan, maar is deze verdwenen. Wanner Google echter op de hoogte is van een URL, probeert Google deze URL enige tijd te crawlen. Dat is normaal, maar als je dat wilt voorkomen, kun je indexering blokkeren, toegang blokkeren of een 301-omleiding gebruiken (indien van toepassing).
Rapport op het hoogste niveau
Het rapport op het hoogste niveau geeft de indexstatus van alle pagina’s weer die Google heeft geprobeerd te crawlen op je site, gegroepeerd op status en reden.
Status
Iedere pagina van je website kan een van de volgende statustypen bevatten:
- Fout: de pagina is niet geïndexeerd. Bekijk de onderstaande beschrijving om meer informatie over het specifieke fouttype te bekijken en hoe je deze fout kunt oplossen.
- Waarschuwing: De pagina is wel geïndexeerd of geïndexeerd geweest. Maar het bevat een probleem waarvan je op de hoogte moet zijn.
- Uitgesloten: Deze pagina van je website is niet opgenomen in de index om een reden waarop je zelf geen invloed hebt. De pagina kan zich in een tussenfase bevinden van het indexeringsproces of je hebt de pagina zelf uitgesloten (bijvoorbeeld door een noindex-instructie).In dit laatste geval reageert de pagina zoals verwacht.
- Geldig: De pagina is geïndexeerd.
Reden
Elke status (fout, waarschuwing, uitgesloten en geldig) kan een specifieke reden hebben. De gegevens in de tabel zijn gegroepeerd op reden. Iedere rij kan een of meerdere URL’s beschrijven. Bekijk de beschrijvingen van statustypen hier onder voor een uitleg van elk statustype en hoe je dit kunt oplossen.
Validatie
De status van een door de gebruiker gestarte validatiestroom voor dit probleem. Je dient prioriteit te geven aan problemen waarbij de validatie mislukt of niet is gestart.
Dropdownfilter voor URL-ontdekking
Met de dropdownfilter boven het diagram kun je indexresultaten filteren op basis van het mechanisme waarmee Google de URL heeft gevonden. De volgende waarden zijn beschikbaar:
- Alle bekende pagina’s [standaard]: Geeft alle door Google ontdekte URL’s weer die op alle mogelijke manieren zijn ontdekt.
- Alle verzonden pagina’s: Geeft alleen pagina’s weer die zijn verzonden in een sitemap via Google Search Console, een robots.txt bestand of een sitemap-ping.
- Specifieke sitemap-URL: Geeft alleen URL’s weer die zijn verzameld in een specifieke sitemap die is verzonden via Google Search Console. Als dit een sitemap-index is, worden alle URL’s in alle opgenomen sitemaps vermeld.
Een URL wordt beschouwd als verzonden via een sitemap, zelfs als deze ook via een ander mechanisme is ontdekt (bijvoorbeeld door organisch crawlen vanaf een andere pagina).
Gedetailleerd rapport op status en reden
Wanneer je op rij op de bovenste pagina klikt, worden de details voor een specifiek statustype weergegeven. Het rapport bevat informatie over de volgende redenen:
- Een diagram waarin de URL’s op algemene status (fout, waarschuwing, uitgesloten en geldig) worden weergegeven.
- Een tabel met URL’s op statustype en de laatste keer dat de URL is geïndexeerd.
Let op! Als je een URL ziet is is gemarkeerd met een probleem dat je al hebt opgelost? Wellicht heb je het probleem opgelost nadat Google de pagina voor de laatste keer heeft gecrawld. Indien je een probleem ziet met een URL die je al hebt opgelost, kijk dan even naar de crawl datum van die URL.
- Als de URL na je oplossing opnieuw is gecrawld, kan de oplossing niet worden bevestigd. Controleer en bevestig in dat geval je oplossing en wacht totdat je pagina opnieuw wordt gecrawld.
- Als je URL is gecrawld vòòr de oplossing, kun je wachten tot Google de URL opnieuw heeft gecrawld of kun je beginnen met oplossen (indien weergegeven) klikken en het probleem oplossen via de werkstroom voor probleembeheer.
Problemen met je pagina’s oplossen.
- Kijk of je misschien overeenkomsten kunt vinden met het totale aantal indexfouten of het totale aantal geïndexeerde URL’s en de sparkline voor een specifieke fout. Dit zou een aanwijzing kunnen zijn voor welk probleem de oorzaak is voor je totaal aantal fouten of totale aantal geïndexeerde pagina’s.
- Los problemen op:
- De tabel met URL’s gegroepeerd op ernst en waarschuwing wordt gesorteerd op basis van een combinatie van ernst, het aantal betreffende pagina’s en of deze op dit moment worden gevalideerd. Het is aan te raden deze in de weergegeven standaard volgorde af te handelen.
- Wanneer er een toename in fouten is, zoek je in de rij naar frequentiepieken die op het zelfde moment zijn opgetreden als de foutpieken in de bovenste diagram. Klik op de rij voor meer informatie in het gedetailleerde rapport.
- Klik op een foutrij voor de gedetailleerde pagina met meer informatie (zie hierboven). Lees de beschrijving over het specifieke fouttype voor een mogelijke oplossing voor het probleem.
- Los alle instanties van elke reden op en vraag een validatie aan door op oplossing valideren in de details voor die reden te klikken.
- Je ontvangt meldingen tijdens de voortgang van je validatie, maar je kunt ook na een paar dagen opnieuw controleren of je aantal fouten omlaag is gegaan.
- Verwijder regelmatig het filter voor uitgesloten URL’s, sorteer de URL’s op het aantal betreffende pagina’s en scan ze op ongewenste problemen.
Statusredenen
Dit zijn de mogelijke redenen voor je pagina:
Verzonden versus niet verzonden
Elke keer dat je een indexresultaat met het woord Verzonden ziet, betekent dit dat je Google expliciet hebt gevraagd de URL te indexeren, omdat je deze URL hebt verzonden in een sitemap.
Fout
Pagina’s met fouten zijn niet geïndexeerd.
- Serverfout (5xx): Je server het een fout met het type 500 geretourneerd toen de pagina werd aangevraagd.
- Fout met omleiding: Er is een omleidingsfout opgetreden voor de URL. Dit kan een van de volgende typen fouten zijn: de URL omvatte een te lange omleidingsketen, de URL omvatte een omleidingslus, de omleidings- URL overschreed uiteindelijk de maximale URL-lengte, de omleidingsketen bevatte een onjuiste of lege URL.
- Ingediende URL geblokkeerd door robots.txt: Je hebt deze pagina ingediend voor indexering, maar de pagina wordt geblokkeerd door robots.txt. Test je pagina met de robots.txt tester.
- Ingediende URL gemarkeerd als noindex: Je hebt deze pagina ingediend voor indexering, maar een metatag of HTTP-reactie van de pagina bevat een noindex-instructie. Als je wilt dat deze pagina wordt geïndexeerd, dien je de metatag of HTTP-reactie te verwijderen.
- Ingediende URL is een soft-404: Je hebt deze pagina ingediend voor indexering, maar de server heft een soft-404 geretourneerd.
- Ingediende URL geretourneerd ongeautoriseerd verzoek (401): Je hebt deze pagina ingediend voor indexering, maar Google heeft een 401-reactie (niet geautoriseerd) ontvangen. Verwijder de autorisatievereisten voor deze pagina of geef Googlebot toegang tot je pagina’s door de identiteit van Googlebot te verifiëren.
- Ingediende URL niet gevonden (404): je hebt een niet bestaande URL ingediend voor indexering.
- Probleem met crawlen voor ingediende URL: Je hebt deze pagina ingediend voor indexering en Google heeft een niet gespecificeerde crawlfout aangetroffen die niet onder een van de andere redenen valt. Probeer deze fouten op te lossen met Fetchen als Google.
Waarschuwing
Pagina’s met een waarschuwingsstatus kunnen uw aandacht vereisen en zijn al dan niet geïndexeerd, afhankelijk van het specifieke resultaat.
Geïndexeerd, maar geblokkeerd door robots.txt. De pagina is geïndexeerd ondanks het feit dat deze wordt geblokkeerd door robots.txt (Google volgt altijd de instructies van robots.txt op, maar dit helpt niet als iemand ander links naar de pagina toevoegt). Dit wordt gemarkeerd door een waarschuwing omdat Google niet zeker weet of je de pagina wilt blokkeren in de zoekresultaten. Als je de pagina wilt blokkeren, is robots.txt niet de juiste methode om te voorkomen dat je pagina wordt geïndexeerd. Als je wilt voorkomen dat de pagina wordt geïndexeerd, gebruikt dan de noindex of blokkeer je anonieme toegang tot de pagina door middel van verificatie. Je kunt de robots.txt tester gebruiken om te bepalen door welke regel de pagina wordt geblokkeerd. Vanwege het robots.txt bestand is een fragment dat voor de pagina wordt weergegeven, waarschijnlijk niet optimaal. Indien je niet deze pagina wilt blokkeren, updatet je je robots.txt-bestand om de blokkering van je pagina op te heffen.
Geldig
Pagina’s met een geldige status zijn geïndexeerd.
- Ingediend en geïndexeerd: Je hebt de pagina ingediend voor indexering en deze is geïndexeerd.
- Geïndexeerd, niet ingediend in een sitemap: De URL is gevonden door Google en is geïndexeerd. Het is aan te raden alle belangrijke URL’s in te dienen via een sitemap.
- Geïndexeerd, overweeg om te markeren als canoniek: De URL is geïndexeerd. Omdat er dubbele URL’s zijn, is het aan te raden deze URL expliciet te markeren als canoniek.
Uitgesloten
Deze pagina’s worden meestal niet geïndexeerd, maar meestal is daar bewust voor gekozen.
- Geblokkeerd door tag noindex: Op het moment dat Google probeerde de pagina te indexeren, is er een noindex-instructie aangetroffen, waardoor je website niet is geïndexeerd. Als je niet wilt dat een pagina wordt geïndexeerd, heb je dit goed gedaan. Als je wel wilt dat de pagina wordt geïndexeerd, dien je de noindex instructie te verwijderen.
- Geblokkeerd door tool voor paginaverwijdering: De pagina wordt momenteel geblokkeerd dooreen URL-verwijderingsverzoek. Verwijderingsverzoeken zijn alleen geldig gedurende een bepaalde periode. Na die periode kan Googlebot terugkeren en de pagina indexeren, zelfs als je geen ander verwijderingsverzoek indient. Als je niet wilt dat de pagina wordt geïndexeerd, gebruik je noindex, vereis je verificatie voor de pagina of verwijder je de pagina. Als je een geverifieerde site-eigenaar bent, kun je de tool voor URL verwijdering gebruiken om te kijken wie er een URL-verwijderingsverzoek ingediend.
- Geblokkeerd door robots.txt: Deze pagina wordt met een robots.txt-bestand geblokkeerd voor Googlebot. Je kunt dit verifiëren met de robots.txt tester. Houd er rekening mee dat de pagina wel op een andere manier kan worden geïndexeerd. Als Google andere informatie over deze pagina kan vinden zonder deze te laden, kan de pagina alsnog worden geïndexeerd (hoewel dit minder vaak voorkomt). Je kan voorkomen dat deze pagina door Google wordt geïndexeerd, door het robots.txt-blok te verwijderen en een noindex-instructie te gebruiken.
- Geblokkeerd wegens ongeautoriseerd verzoek (401): Deze pagina is geblokkeerd voor een Googlebot door een verzoek tot autorisatie (401-reactie). Als je wilt dat Googlebot deze pagina crawlt, verwijder je de autorisatievereisten of geef je Googlebot toegang tot je pagina’s door de identiteit van Googlebot te verifiëren.
- Crawlafwijking: Er heeft zich een niet gespecificeerde-afwijking voorgedaan bij het ophalen van deze URL. Dit kan betekenen dat er een 4xx- of 5xx reactiecode wordt geretourneerd. Probeer de pagina op te halen met Fetchen als Google om te controleren of zich problemen met het ophalen voordoen. Deze pagina is niet geïndexeerd.
- Gecrawld – momenteel niet geïndexeerd: De pagina is wel door Google gecrawld, maar niet geïndexeerd. Het zou goed kunnen dat de pagina in de toekomst alsnog wordt geïndexeerd. De URL hoeft niet opnieuw te worden ingediend om te worden gecrawld.
- Gevonden – momenteel nog niet geïndexeerd: De pagina is gevonden door Google, maar nog niet gecrawld. Doorgaans heeft Google in dit geval geprobeerd de URL te crawlen, maar was de site overbelast waardoor Google het crawlen opnieuw moest plannen. Dit is ook de reden waarom de laatste crawldatum leeg is in het rapport.
- Alternatieve pagina met correcte canonieke tag: Deze pagina is een duplicaat van een pagina die Google als canoniek herkent en bevat een correcte verwijzing naar de betreffende canonieke pagina. Je hoeft verder dus niet te doen.
- Dubbele niet HTML-pagina: Een niet-HTML-pagina (bijvoorbeeld een PDF-bestand) is een duplicaat van een andere pagina die Google heeft gemarkeerd als canoniek. Normaal gesproken wordt alleen de canonieke URL weergegeven in Google zoeken. Als je wilt, kun je een canonieke pagina opgeven door de link HTTP-header in een reactie te gebruiken.
- Google heeft een andere canonieke pagina gekozen dan de gebruiker: Deze URL is gemarkeerd als canonieke voor een reeks pagina’s, maar Google denk dat een andere URL een betere canonieke pagina is. Omdat deze pagina als duplicaat wordt beschouwd, is deze pagina niet geïndexeerd. Het is aan te raden deze pagina expliciet te markeren als duplicaat van de canonieke URL. Als je wilt weten welke pagina de canonieke pagina is, klik je op de tabelrij op de zoekopdracht info: uit te voeren voor deze URL. Op die manier kun je de canonieke pagina weergeven.
- Niet gevonden (404): De pagina retourneert een 404-fout wanneer de pagina wordt aangevraagd. De URL is door Google ontdekt zonder expliciet verzoek om deze pagina te crawlen. Google kan de URL op verschillende manieren hebben achterhaald. Zo kan een andere pagina een link naar de URL bevatten of bestond de pagina al eerder en is deze verwijderd. Googlebot blijft de URL waarschijnlijk gedurende een bepaalde periode proberen. Er is helaas geen manier om aan te geven dat Googlebot een URL permanent moet vergeten. Wel is het zo dat de pagina steeds minder vaak wordt gecrawld. 404-reacties vormen geen probleem, indien ze als zodanig zijn bedoeld. Als je pagina is verplaatst, gebruik je een 301-omleiding naar de nieuwe locatie.
- Pagina verwijderd wegens juridische klacht: De pagina is uit de index verwijderd vanwege een juridische klacht.
- Pagina met omleiding: De URL is een omleiding en is daarom niet toegevoegd aan de index.
- In afwachting van crawlen: De pagina staat in de wachtrij om te worden gecrawld. Check na een paar dagen nog eens of de pagina is gecrawld.
- Soft 404: Het paginaverzoek retourneert een reactie die als soft 404-reactie wordt beschouwd. Dit betekent dat er een gebruiksvriendelijke bericht met de tekst niet gevonden wordt weergegeven zonder een 404-reactiecode. Het is aan te raden een 404-reactiecode te retourneren voor pagina’s die niet zijn gevonden om te voorkomen dat de pagina’s worden geïndexeerd.
- Ingediende URL is verwijderd: Je hebt deze pagina ingediend om te worden geïndexeerd, maar de pagina is om onbekende reden verwijderd.
- Ingediende URL niet geselecteerd als canoniek: De URL is en van de URL’s uit een set dubbele URL’s zonder een expliciet gemarkeerde canonieke pagina. Je hebt expliciet gevraagd deze URL te indexeren. maar omdat de URL een duplicaat en een andere URL volgens Google een betere kandidaat voor de canonieke pagina is, heeft Google deze pagina niet geïndexeerd. In plaats daarvan is de door Google geselecteerde canonieke pagina geïndexeerd. Het verschil tussen deze status en Google heeft een andere canonieke pagina gekozen dan de gebruiker is dat je in dit geval expliciet hebt verzocht de URL te indexeren.